
Physics Journal, Vol. 2, No. 4, July 2016 Publish Date: Aug. 16, 2016 Pages: 253-265
The Improvement of Routing Operation Based on Learning Automata an Enrichment of Dynamically Detected Invariants in Arrays Case
Faramarz Karamizadeh1, Hamid Parvin2, 3, *, Ahad Zolfagharifar2
1Department of Electrical and Computer Engineering, Shiraz University, Shiraz, Iran
2Department of Computer Engineering, Nourabad Mamasani Branch, Islamic Azad University, Nourabad Mamasani, Iran
3Young Researchers and Elite Club, Nourabad Mamasani Branch, Islamic Azad University, Nourabad Mamasani, Iran
Abstract
The subject of routing in computer networks has got a considerable place in recent years. The reason of that is the determining role of routing in the efficiency of these networks. Service quality and security are considered as the most important challenges of routing due to the lack of reliable methods. Routers use routing algorithms for finding the best path to destination. When we speak about the best rout, we consider parameters such as the number of hops, changing time and the cost of communicational costs of sending packets. Using smart factors locally and nationally, in this thesis it has been tried to improve routing operations. The ant colony algorithm is a multifactor solution for optimization issues which has some models based on collective intelligence of ants and has been applicable by converting to an efficient technology in computer networks. Although the ant is a simple creature, but a colony of ants can do useful tasks such as finding the shortest route toward food and sharing this information with other ants through leaving a chemical material named Pheromone. This algorithm includes three stages. The first phase is clustering network nods to smaller colonies, this phase is accomplished using learning automata in accordance with network need; for example placing the nods which will have more interaction in a cluster in future. Second phase is finding the routes of network by ants; and the third phase is sending network traffic to destination through the found routs by ants.
Keywords
Routing, Computer Networks, The Ant Colony Algorithm, Learning Automata
Received: August 20, 2015
Accepted: July 20, 2016
Published online: August 16, 2016
@ 2016 The Authors. Published by American Institute of Science. This Open Access article is under the CC BY license. http://creativecommons.org/licenses/by/4.0/
Contents
1. Introduction
Today, many centers of data store in the world look for methods in order to increase the accountability of demands as well as providing efficient and optimal service; so that, in order to do this in many data centers, the methods such as hiding information, physical resources management such as routers, load division, controlling extra load, and using the mechanisms of controlling service quality are used. One reason which causes the rate of a router’s efficacy decrease after a while from starting is the reduction of the buffer size and removal operation of packets by routers which at least leads to the increase in the time of responding demands or many of them do not get any response [1].
The discussion of routing in computer networks has become especially significant in recent years. The reason of that is determining role of routing in the efficiency of these networks. The quality of services and security are from the most important challenges of routing due to the lack of secure methods.
2. Problem Statement
Routers use routing algorithms for finding the best path to destination. When we say the best rout, we consider parameters such as the number of hops, changing time and the communicational costs of sending packets. There is a high variety in protocols and routing algorithms for network communication. In traditional routing, the tables of routing get updated by exchanging routing information among routers. The existence of complicated network problems such as appropriate routing, balance and adjusting load rate and controlling density and congestion require a smart and developed technology to solve such problems. Nowadays, working on developing smart systems inspired by nature is considered as one of the very popular areas of collective intelligence. For example, inspired by ants’ routing, some algorithms are proposed which use mobile factors for routing the data networks.
Generally when there is a large change in a big network, it needs to be informed by all network’s nods while the importance of these changes is more for the nods they work with more. Therefore dividing network to smaller sets leads the nods of each set to keep only the routing information of that set and get released from knowing all changes in the whole network. Therefore, distributed routing is accomplished. Here, even in case of changes in network, because of this very division, these changes would be related to a small part of network and others will be less affected by that. Therefore on one hand, routing can be operated without considering the changes of network out of the set and on the other hand, because of exchanging less volume of extra data out of sets and routing inside them, the speed of routing will be more.
Numerous clustering algorithms have been designed for computer networks up to now. The main goal of clustering-based protocols is using an appropriate method for optimum use of network resources and consequently, increase in the network lifespan [2]. In one hand, clustering method has the network scalability which is one of the most important parameters of designing in wireless sensor networks [3,4]. In each cluster, one nod is considered as the head cluster and the other nods are considered as the members of cluster, each nod can be a member of only one cluster [2]. Since collecting and sending information of environment to the base station is the duty of the head clusters, consequently, energy consumption in the head clusters will be more than the other nods; therefore the remaining energy of nods can be a criterion for choosing head cluster [5]. Clustering algorithms are divided into two groups of concentrated and distributed. Concentrated clustering algorithms require general knowledge of network and computational overhead and they are not suitable for sensory nods or limited resources. On the other hand, in distributed clustering algorithms, it is usually decided based on the local information, generally distributed clustering methods are less expensive than concentrated ones [6]. Therefore the components we face in evaluating an optimum routing pattern include:
• Increasing the speed of sending and receiving data through the network
• Dynamic routing in the network
• Eliminating congestion in routers
• More security of packets
• Restricting network instability in an area and preventing from its proliferation to the other areas of the network
• Obtaining new method of optimizing routing algorithms
• Comparing routing algorithms by the obtained method in analytical method of thesis
• Hypothetical and theoretical methods for direct addressing of packets
• Reducing the overhead on the router
• Increasing the speed of convergence
3. Concepts
Routing: This process includes choosing the best rout in network and an effective role it plays in sending data in a network. Routing is applicable for several networks such as telephone network, internet and transferring. This routing can be the reason of sending rational packets from source to destination.
The ant colony algorithm: the ant colony algorithm is inspired by studies and observations on ants’ colonies. These studies have shown that the ants are sociable creatures which live in colonies; and their behavior is majorly towards surviving colony than surviving one part of that. One of the most important and interesting behavior of ants is finding food and especially how they find the shortest route between food source and their nest.
The process of finding the shortest route by ants has interesting characteristics, first of all is interoperability and self-organizing of that. There is also no central control mechanism. The second feature is its high power. The system includes a lot of factors which each of them is not important by itself; therefore, even the damage of an important factor does not affect system’s efficacy a lot. The third feature is that the process is a comparison trend. Since the behavior of no ant is determined and some of ants choose longer rout, system can adapt itself to the environmental changes; and the last feature is that, the mentioned process can be developed and can be as big as you want. The same features inspired designing algorithms which are practical in problems which require these features [1-13].
Learning automata: learning automata are one of the reinforcement learning models where automata make an optimum task considering the performed action and environment feedback. Final goal of automata is learning to choose the best action among its actions. The best action is the action which maximizes the possibility of getting reward from the environment.
4. Related Works
Genetic algorithm was proposed in 1975 by John Holland. This algorithm is a random searching technique based on human evolution hypothesis. Different aims have caused creating genetic algorithm during past 30 years. Genetic algorithms are in fact random searching techniques which are based on natural mechanisms and the genetics laws of combination and mutations.
In 1991, Dorigo and Clorini proposed metaheuristic ant algorithms for solving the problems capable for separability. This algorithm has some features such as simple adaptability in the usage, so that it is used by the least changes in combinational optimization problems such as quadratic assignment problem and the timing of work in workshops.
In 1996 Dorigo and Jembardla created some expressions in ant algorithms and proposed the ant colony algorithm. This algorithm is different from the previous one in three factors as following [14-24]:
• The transfer law of position that directly controls the effects of new and previous nods on algorithm.
• General updating law which is only used in nods that belong to ant rout (the best ones).
• When the ants create an answer, the law of local updating is used.
In 1960s Y. Z. Tsypkin introduced a simple method for simplifying learning problems to a problem for recognizing optimum parameters and using hill climbing methods for solving that. Tsetlin et al. started working on learning automata at the same time. The concept of learning automata was first discussed by him. Tsetlin was interested in modeling the behaviors of biologic systems and introduced a certain automata which acted in a random environment as a model for learning. In later researches, learning was also used in engineering systems.
Another approach which was proposed by Viswanatan and Narendra was considering the problem in the way of finding an optimum action among a set of permitted actions of a random automaton. The difference between the two recent methods is that in the first one, the space of parameters is updated in each repetition; but in the second one, the possibility space is updated. After that, the most of performed works in learning automata theory were performed after the introduced rout by Tsetlin. Varshavski and Vorontsova proposed the learning automata or variable structure that used to update the possibilities of its actions and consequently, it caused reduction of the number of modes compared to the certain automata [24-46].
The initial efforts for using learning automata in control functions were accomplished by Fu et al. such as the functions of learning automata in parameter estimation, pattern recognition and game theory. Mclaren investigated the methods of linear updating and their features and after that Chandrasekar and Shen investigated non-linear updating methods.
The book of Narendra and Thathachar under the title of Learning Automata: Theory and application is an introduction to the automata theory that includes all performed researches by the late 1980. The numerous examples and functions of learning automata have been also proposed by Najim and Pznyak in a book under the title of learning automata: theory and application.
5. Recommended Method
Using smart factors locally and nationally, routing operation is tried to be improved in this study. The ants’ colony algorithm is a multifactor solution for optimization which has some models based on collective intelligence of ants and has been applicable by converting to an efficient technology in computer networks.
This algorithm includes three levels. The first phase is clustering network nods to smaller colonies, this phase is accomplished by using learning automata in accordance with the network’s need; for example placing the nods which will have more interaction in future in a cluster. Second phase is finding the routes of network by ants and the third phase is sending network traffic to destination through the found routs by ants [45-58].
Learnings automata is used in this study in order for clustering. Each selected action is evaluated by a possible environment, and as a result, the automata is given a positive or negative signal form. Automata use this response in choosing their later action. The ultimate goal is that automata learn to choose the best action among their actions. In fact, clustering can be done by using learning automata considering behavioral model of transferring data among network members. Congestion can be also predicted and it can transfer traffic load to other routes.
We also use direct addressing method that causes eliminating process in routers. here, without packets spend time in router, it will pass router directly and only its report in router will reach the sender system; this action causes acceleration in sending and receiving packets and more security of data. As it was mentioned, we have considered in this study the pioneer problem of routing in communication networks; and we have also concentrated on routing for datagram networks of a wide area with irregular topology and best-effort service; for example, the most considerable network in this field is internet. Comparison routing algorithm that is recommended here is called ant net that the distribution and multifactor algorithm match it well with routing problem. Designing this algorithm is routing by inspiring previous works in ant colony and generally by concept of signaling that is as indirect communications among people through local changes, constantly (or gently changing) derived by the environment. In optimizing ant colony, each one of ants uses a set of simultaneous artificial local random searching strategy to make a solution for their combinational problem. In this regard, ant algorithm can be placed in parallel trend for acceleration and increase the speed of that as more as possible. Some ants collectively look for solutions with high quality by an indirect cooperation, they obtain some information about the structure of problem from each other and use collected data for achieving their solution [59-75].
Using a random routing policy and local and private information (general), the ants discover the network and collect suitable data about that simultaneously and irregularly. While searching, the ants make local network routing and probabilistic routing tables adaptively. This information is collected using indirect and uncoordinated communication by the other ant’s colleagues.
The different behavior of AntNet has been investigated in this research in two versions and compared with algorithms below: Open shortest path first (OSPF), Shortest Path First (SPF), Bell Manford comparative distribution (BF), Q routing and PQ routing. We tested algorithm in a real empirical condition which was a basic private network NTT in Japan which had been produced from 100 and 150 network nods randomly. In all cases the AntNet algorithm shows that it has the best performance and its behavior creates the most sustainable mode and it also has the best performance among SPF and BF competitors [76-89].
Two versions of AntNet were implemented that are respectively AntNet-CL and AntNet-CO. AntNet-CL (that algorithm which was simply called AntNet) is the first implementation and we developed it for managing routing in best-effort networks while AntNet-CO is a more reactive version than AntNet-CL that provides the requirements of routing in connection-oriented high speed networks which are in the form of best-effort.
AntNet-CL algorithm is first described informally; then, the differences between it and AntNet-CO will be investigated. In AntNet-CO general behavior is same as above with this difference that:
Pioneer ants use the high priority queue as rollback ants.
They don’t have stack memory to store information about time and the length of their journey from source to destination.
Rollback ants change routing tables in each nod which they visit by estimating journey time.
This estimation is calculated in each group of K by using a statistical model Llk the evacuation of dynamics of a local link, the simplest model L has been used in this study that considering the number of bits q1 from data packets waiting in L queue, virtual time of journey for reaching the neighbor is as ![]() where
where ![]() is bandwidth of link,
is bandwidth of link, ![]() is the size of ant packet and
is the size of ant packet and ![]() is link delay. In both two algorithms of AntNet-CL and AntNet-CO, pioneer ants apply a random policy which leads to discovering a good route: in AntNet-CL pioneer ants are exactly behaved like data packets and the experience of their delay is used by rollback ants, and as a result, the quality of passed routs is calculated; this is while, in AntNet-CO pioneer ants rapidly discover a route that is used by rollback ants that is obtained by estimating journey time for achieving goal and using L model.
is link delay. In both two algorithms of AntNet-CL and AntNet-CO, pioneer ants apply a random policy which leads to discovering a good route: in AntNet-CL pioneer ants are exactly behaved like data packets and the experience of their delay is used by rollback ants, and as a result, the quality of passed routs is calculated; this is while, in AntNet-CO pioneer ants rapidly discover a route that is used by rollback ants that is obtained by estimating journey time for achieving goal and using L model.
In the following, for more improvement of AntNet-CO method, each of the ants was equipped with some bits that are zero at first. These bits can be considered as an ant lifespan and an amount of its life will be spent with each inappropriate replacing or how close the ant is to the goal. In picture below, a schematic view of data structure of an ant is shown that some of its life has been spent.
As it can be seen in Figure 1, the data about what neighbor nod the ant has to go is stored in route data and with what speed the ant should do this calculations and the type of its performance functions in control data, how much its effects will remain in the network in time data and how much they live is stored in experience and it has caused the creation of a kind of random algorithm that practically there is no need for manual elimination of network data anymore, because as it was said, in the proposed algorithms the problem should be investigated whether ant is in round or not which causes pressure on the inside resources of network.

Figure 1. The structure of an ant in proposed algorithm.
In algorithm, the life of an ant is considered as the number of network nods, that is to say that if the number of the seen hops by that is more than network nods, we can surely know that it is recluse; then, that ant’s overhead computations will be more than its benefits and consequently, with N waiting for the response of that ant, if the rollback ant does not return, we send another pioneer ant. In this work, ![]() is considered as 8 bits in which each of ants will be initialized separately considering the nod where it is produced in and considering the pre-learned values. in case that the system has not learned anything, it learns
is considered as 8 bits in which each of ants will be initialized separately considering the nod where it is produced in and considering the pre-learned values. in case that the system has not learned anything, it learns ![]() . First when the nod is lightened, it sends some standby signals for its neighbor to announce its presence; and after investigating the link received, the neighbors send a welcome signal to newcomer nod with their
. First when the nod is lightened, it sends some standby signals for its neighbor to announce its presence; and after investigating the link received, the neighbors send a welcome signal to newcomer nod with their ![]() for the newcomer nod to have initial estimation of
for the newcomer nod to have initial estimation of ![]() , then through getting the mean from these values of
, then through getting the mean from these values of ![]() , it can have a uniform estimation of the received signals; so we have:
, it can have a uniform estimation of the received signals; so we have:
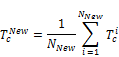
That ![]() shows the number of newcomer neighbors. Now, the ants play the role of messenger as well as data collector, so that they also move
shows the number of newcomer neighbors. Now, the ants play the role of messenger as well as data collector, so that they also move ![]() from their source; that is to say that if they reach a nod which its
from their source; that is to say that if they reach a nod which its ![]() is smaller than the ant’s
is smaller than the ant’s ![]() , then nod’s
, then nod’s ![]() will change to that bigger value [79-93].
will change to that bigger value [79-93].
6. The Results of Simulation
MATLAB software has been used for simulation; we first considered a network with 100 nods of Cisco RVxx routers and connected them to each other randomly and tested our routing then using different protocols. For creating virtual traffic, we used Polson distribution and in fact, time distance among demands will have an exponential distribution.
6.1. Simulation Context and Evaluating System
We used throughput rate (bits delivery / s), delayed data packets (s) and routing overhead (broadband routing / available bandwidth), as criteria for comparing among algorithms. In our algorithm, one ant is sent for collecting data every 3 seconds whose size is as ![]() in which
in which ![]() is the number of passed hops in the network which their volume will increase by increasing the path of an ant [147-153].
is the number of passed hops in the network which their volume will increase by increasing the path of an ant [147-153].
We considered 7 bits for life parameters because each ant has to go ahead averagely ![]() hops that in this case it has to have at least tree’s lifespan. Rollback pioneer ants both have the same structure that exist in 28 bits of time and control data related to Pheromone which has been explained before.
hops that in this case it has to have at least tree’s lifespan. Rollback pioneer ants both have the same structure that exist in 28 bits of time and control data related to Pheromone which has been explained before.
In SPF, OSPF and BF algorithms, it has also assumed that time distance between both communicational signals is equal and in every 0.8 to 3 seconds. We considered 24 megabytes for each session; this value of data can be sent or received from random source or destination [94-103].
These experiments have been performed on a 16 core server (core i7) that had 128 gigabytes of ram and for each performance, it required about 43 hours. For each result of table, 300 repetitions have been done to eliminate the effect of being random. Totally 6 algorithms are implemented, the results have been obtained as diagram that will be investigated as follows:
6.2. Experiments
The first experiment
1000 files of 2 megabytes were randomly sent to the random destinations from two random points in network in this experiment and for each of the 6 algorithms, throughput coefficient of 5 was calculated and then whole test was repeated for 1000 other files as far as implementing this experiment for 300 times then in time period the mean of throughput rate was calculated in order to achieve the diagram below.
By doing experiment just for 1 time, the results of experiments have many fluctuations because of this, we repeated 300 times to achieve correlation in observations.
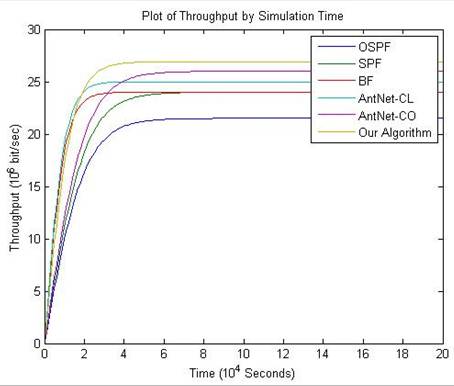
Figure 2. The changes of throughput coefficient of different algorithms during the time.
As it is clear in this figure, it can be clearly understood that proposed algorithm in this study has the highest throughput coefficient in all other algorithms while OSPF has the lowest one.
Because the nature of network based on packet has the explosion feature 6, the algorithms which are more in accordance with this feature will be more ideal for us. Therefore as it can be seen in figure 2, after a while, all algorithms get sustainable but their performance will be more important for us in the first seconds that it can be seen among three proposed algorithms in this study, AntNet and BF covered explosion feature of network better. In other word, we consider the algorithms which their change slopes are more at the beginning of demand. OSPF cannot be logically considered inefficient because the routers which are required for such an algorithm will have simpler equipment; for example a processor which is needed for this algorithm does not require cache 7high.
The second experiment
The conditions of previous experiments were implemented 50 times for the whole of this experiment; then, in each size of network, figure 3 was obtained by reaching the mean of throughput coefficient value.
In this experiment, we also faced many fluctuations with only 1 time of implementation; so, the work was repeated 50 times to obtain reliable results. The distance between each experiment is 500 nods that means in each experiment when obtained results 50 times, 500 nods were randomly added to the current network and the results of throughput coefficient is calculated in new network. In each time experiment of network, network communication links between routes were randomly changed not to get specified results for a specific network.
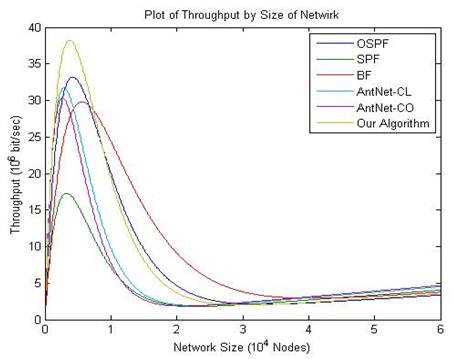
Figure 3. The changes of throughput coefficient by changing the size of network.
As it can be seen in figure 3, all algorithms show high throughput coefficient for a specific period and it is because of the smaller size, routing algorithms require faster change of their routing tables and also the algorithms based on ants colony algorithm in case of being small have less freedom for transferring a packet of information to its destination; but for bigger networks, the more the number of nods increases, the more the length of routes between source and destination gets higher [103-112].
But as it can be seen in figure 3, from one point the more we make the size of network bigger, the throughput increases a little. The reason of this phenomenon is shorter routes that will increase by increasing the number of nods.
The proposed algorithm shows the highest coefficient of throughput rate in a period where all algorithms reach their maximum throughput coefficient; but in terms of sustainability, with bigger size of network algorithm BF changes its throughput coefficient later which is because of the algorithm structure that only changes its routing table when the packets are lost. In the proposed algorithm with making the size of network bigger, the component of experience in ants loses its effectiveness and acts like algorithms AntNet-CO and AntNet-CL; therefore, a good adjustment can be achieved which is specific for that network by a trade-off between the size of proposed algorithm packets and the rate of throughput.
In other words, instead of 8 bit space for storing experience of ants, we can use 16 or 32 bits but considering the length of packets, there will be extra overhead on system. On the other hand, if this memory is low this specified space will not have positive effect on a big network as it was explained before.
Algorithm SPF has had weaker results than the changes of network length; that is because of requiring the shortest route and with increasing the length of network, the time of this algorithm will be three times more than its previous power [135-146].
The last point which has to be mentioned is that in this network, we have a base noise that the bigger the length of routes gets, the more likely the error will be and consequently throughput coefficient will decrease significantly which has been shown accurately in this figure.
The third experiment
In this experiment and also from two random points in the network, we sent 10 kilobyte 1000 files to a random destination. For each one of the two algorithms, we calculated the number of hops which have found randomly in their route and the conditions of the previous experiments repeated for this experiment about 20 times; then figure 4 was obtained in each size of networks with calculating mean from the average number of hops.
Figure 4. The average number of hops that the proposed algorithm and AntNet-CO showed for their routes.
The created noise in this figure is because of the few number of repeating algorithm; and due to the time consumption and resolution in result, it was avoided to repeat it more. Algorithm AntNet-CL creates generally longer rotes than AntNet-CO algorithm and accordingly, it has not been shown in figure 4. In this algorithm, the time of making random routes is eliminated from results in order not to make mistakes in conclusion [112-119].
The fourth experiment
The other criterion which can help us to achieve ideality of an algorithm is the length of routes that it finds for routing among points. As a result, except algorithms such as OSPF, BF and SPF that spend their time exactly on finding the shortest route and finally get the shortest route or the shortest approximate route, related algorithms to the ant algorithm were compared with each other. The conditions of previous experiences were implemented 30 times in this experiment; then, in each file size, we obtain the following results with calculating the mean of the packets delivery delay.
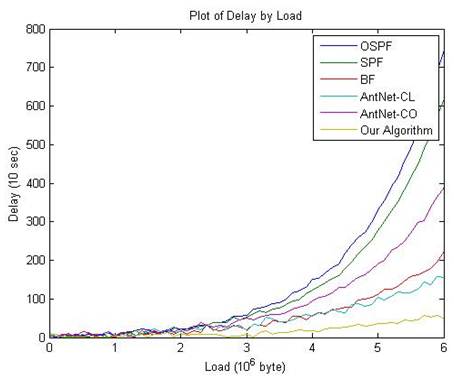
Figure 5. Average rate of delay based on network load.
As it can be seen in figure 5, the rate of delay in the proposed algorithm has the least value among all algorithms; the reason is that after delivering the first packet, its experience bits to next packets till the network does not have a specific change in terms of congestion 0.8 change in sending rate or structure changes, these bits are used as the experience of the next packets.
Being more accurate, it can be understood that AntNet-CO algorithm and AntNet-CL are in next ranks in terms of delay time. Generally the algorithms which work appropriate with finding the shortest route have higher delay time than genetic algorithms [119-134].
The other reason which can be mentioned for low delay of algorithm is that learning automata that is defined for learning parameter of each ant’s experience will be learnt after a short time; hence, the complete learning of ant is not required therefore a short time after getting parameter, that parameter can be considered implicitly for each of the other packets and it can even reduce the time of delay.
7. Conclusion
This research tried to optimize direct routing problem in communication networks suing ant algorithm and learning automata system. We concentrated on routing for datagram networks of a wide area with irregular topology and best-effort service.
In this study in routing tables for a specific destination in structural data, they are kept in a priority queue rather than ![]() and as a result of using this data, the structure does not search for the best route with less
and as a result of using this data, the structure does not search for the best route with less ![]() . If there is a destination with the least
. If there is a destination with the least ![]() then the router send that data to a specific router; but with specific destination, if there was no route toward it, then there will remain a discoverer packet, sent and waiting rollback packet and consequently at the time of learning, delay may happen; but because our assumption is on convergence, then with the first learning, the results will be sent for others as well and as a result, the learning will be faster and ultimately the algorithm gives us better results.
then the router send that data to a specific router; but with specific destination, if there was no route toward it, then there will remain a discoverer packet, sent and waiting rollback packet and consequently at the time of learning, delay may happen; but because our assumption is on convergence, then with the first learning, the results will be sent for others as well and as a result, the learning will be faster and ultimately the algorithm gives us better results.
The algorithm AntNet-CO is more appropriate for big files, static communications and the networks with low changes; because the steady mode after proposed algorithm has the most rate of throughput coefficient. This algorithm was firstly implemented in MATLAB programming software then in C++.
When the size of network gets bigger in each structure of network, different routes created will have different lengths; therefore, the other conclusion which we could draw was that the bigger the network is, the more unpredictable behaviors will be. So, if we want to unite the obtained diagram, more repetition will be needed for bigger networks. The other point is that the preference of proposed algorithm is in a specific period because in bigger sizes, these two diagrams have got closer to each other averagely.
Also in case of increasing the length of route, the ants rarely can inform other ants about the history of their passing routes so each one of ants will remember the route of previous ant in the best case.
The slope of passed routes’ length changes based on the size of network is linear in the proposed algorithm but AntNet-CO draws a logarithm.
References
- K. G. Parthiban and S. Vijayachitra, Spike Detection from Electroencephalogram Signals with Aid of Hybrid Genetic Algorithm-ParticleSwarm Optimization, Journal of Medical Imaging and Health Informatics, 5, 936-944 (2015).
- I. Barwal and S. C. Yadav, Rebaudioside A Loaded Poly-D,L-Lactide-Nanoparticles as an Anti-Diabetic Nanomedicine, Journal of Bionanoscience, 8, 137-140 (2014).
- M. A. Khanday and A. Najar, Maclaurin's Series Approach for the Analytical Solution of Oxygen Transport to the Biological Tissues Through Capillary Bed, Journal of Medical Imaging and Health Informatics, 5, 959-963 (2015).
- H. Huang and F. Yang, An Interpretation of Erlang into Value-passing Calculus, Journal of Networks, 8(7), 1504-1513 (2013).
- S. Adnani, F. Sereshki, H. Alinejad-Rokny and H. Kamali-Bandpey, Selection of Temporary Ventilation System for Long Tunnels by Fuzzy Multi Attributes Decision Making Technique (Fuzzy-Madm), Case Study: Karaj Water Conveyance Tunnel (Part Et-K) in Iran, American Journal of Scientific Research, 29, 83-91 (2011).
- H. B. Kekre and T. K. Sarode, Vector Quantized Codebook Optimization Using Modified Genetic Algorithm, IETE Journal of Research, 56(5), 257-264 (2010).
- M. Gera, R. Kumar, V. K. Jain, Fabrication of a Pocket Friendly, Reusable Water Purifier Using Silver Nano Embedded Porous Concrete Pebbles Based on Green Technology, Journal of Bionanoscience, 8, 10-15 (2014).
- M. S. Kumar and S. N. Devi, Sparse Code Shrinkage Based ECG De-Noising in Empirical Mode Decomposition Domain, Journal of Medical Imaging and Health Informatics, 5, 1053-1058 (2015).
- M. Mokhtari, H. Alinejad-Rokny and H. Jalalifar, Selection of the Best Well Control System by Using Fuzzy Multiple-Attribute Decision-Making Methods, Journal of Applied Statistics, 41(5), 1105-1121 (2014).
- C. Zhou, Y. Li, Q. Zhang and B. Wang, An Improved Genetic Algorithm for DNA Motif Discovery with Gibbs Sampling Algorithm, Journal of Bionanoscience, 8, 219-225 (2014).
- R. Bhadada and K. L. Sharma, Evaluation and Analysis of Buffer Requirements for Streamed Video Data in Video on Demand Applications, IETE Journal of Research, 56(5), 242-248 (2010).
- M. Kurhekar and U. Deshpande, Deterministic Modeling of Biological Systems with Geometry with an Application to Modeling of Intestinal Crypts, Journal of Medical Imaging and Health Informatics, 5, 1116-1120 (2015).
- S. Prabhadevi and Dr. A.M. Natarajan, A Comparative Study on Digital Signatures Based on Elliptic Curves in High Speed Ad Hoc Networks, Australian Journal of Basic and Applied Sciences, 8(2), 1-6 (2014).
- X. Jin and Y. Wang, Research on Social Network Structure and Public Opinions Dissemination of Micro-blog Based on Complex Network Analysis, Journal of Networks, 8(7), 1543-1550 (2013).
- O. G. Avrunin, M. Alkhorayef, H. F. I. Saied, and M. Y. Tymkovych, The Surgical Navigation System with Optical Position Determination Technology and Sources of Errors, Journal of Medical Imaging and Health Informatics, 5, 689-696 (2015).
- R. Zhang, Y. Bai, C. Wang and W. Ma, Surfactant-Dispersed Multi-Walled Carbon Nanotubes: Interaction and Antibacterial Activity, Journal of Bionanoscience, 8, 176-182 (2014).
- B. K. Singh, Generalized Semi-bent and Partially Bent Boolean Functions, Mathematical Sciences Letters, 3(1), 21-29 (2014).
- S. K. Singla and V. Singh, Design of a Microcontroller Based Temperature and Humidity Controller for Infant Incubator, Journal of Medical Imaging and Health Informatics, 5, 704-708 (2015).
- N. Barnthip and A. Muakngam, Preparation of Cellulose Acetate Nanofibers Containing Centella Asiatica Extract by Electrospinning Process as the Prototype of Wound-Healing Materials,Journal of Bionanoscience,8, 313-318 (2014).
- R. Jac Fredo, G. Kavitha and S. Ramakrishnan, Segmentation and Analysis of Corpus Callosum in Autistic MR Brain Images Using Reaction Diffusion Level Sets, Journal of Medical Imaging and Health Informatics, 5, 737-741 (2015).
- Wang, B. Zhu, An Improved Algorithm of the Node Localization in Ad Hoc Network, Journal of Networks, 9(3), 549-557 (2014).
- T. Buvaneswari and A. A. Iruthayaraj, Secure Discovery Scheme and Minimum Span Verification of Neighbor Locations in Mobile Ad-hoc Networks, Australian Journal of Basic and Applied Sciences, 8(2), 30-36 (2014).
- Y. Zhang, Z. Wang and Z. Hu, Nonlinear Electroencephalogram Analysis of Neural Mass Model, Journal of Medical Imaging and Health Informatics, 5, 783-788 (2015).
- S. Panwar and N. Nain, A Novel Segmentation Methodology for Cursive Handwritten Documents, IETE Journal of Research, 60(6), 432-439 (2014).
- E. Hasanzadeh, M. Poyan, and H. Alinejad-Rokny, Text Clustering on Latent Semantic Indexing with Particle Swarm Optimization (PSO) Algorithm, International Journal of Physical Sciences, 7(1), 116-120 (2012).
- H. Mao, On Applications of Matroids in Class-oriented Concept Lattices, Mathematical Sciences Letters, 3(1), 35-41 (2014).
- M. Ahmadinia, M. R. Meybodi, M. Esnaashari and H. Alinejad-Rokny, Energy-efficient and multi-stage clustering algorithm in wireless sensor networks using cellular learning automata, IETE Journal of Research, 59(6), 774-782 (2013).
- D. Kumar, K. Singh, V. Verma and H. S. Bhatti, Synthesis and Characterization of Carbon Quantum Dots from Orange Juice, Journal of Bionanoscience, 8, 274-279 (2014).
- V. Kumutha and S. Palaniammal, Enhanced Validity for Fuzzy Clustering Using Microarray data, Australian Journal of Basic and Applied Sciences, 8(3), 7-15 (2014).
- Y. Wang, C. Yang and J. Yu, Visualization Study on Cardiac Mapping: Analysis of Isopotential Map and Isochron Map, Journal of Medical Imaging and Health Informatics, 5, 814-818 (2015).
- R. Su, Identification Method of Sports Throwing Force Based on Fuzzy Neural Network, Journal of Networks, 8(7), 1574-1581 (2013).
- L. Feng, W. Zhiqi and L. Ming, the Auto-Detection and Diagnose of the Mobile Electrocardiogram, Journal of Medical Imaging and Health Informatics, 5, 841-847 (2015).
- D. Deepa, C. Poongodi, A. Bharathi, Satellite Image Enhancement using Discrete Wavelet Transform and Morphological Filtering for Remote Monitoring, Australian Journal of Basic and Applied Sciences, 8(3), 27-34, (2014).
- R. Sarma, J. M. Rao and S. S. Rao, Fixed Point Theorems in Dislocated Quasi-Metric Spaces, Mathematical Sciences Letters, 3(1), 49-52 (2014).
- T.Gopalakrishnan and P. Sengottvelan, Discovering user profiles for web personalization using EM with Bayesian Classification, Australian Journal of Basic and Applied Sciences, 8(3), 53-60 (2014).
- H. Jianfeng, M. Zhendong and W. Ping, Multi-Feature Authentication System Based on Event Evoked Electroencephalogram, Journal of Medical Imaging and Health Informatics, 5, 862-870 (2015).
- R. Kumar and I. Saini, Empirical Wavelet Transform Based ECG Signal Compression, IETE Journal of Research, 60(6), 423-431 (2014).
- N. Shukla, P. Varma and M. S. Tiwari,Kinetic Alfven wave in the presence of parallel electric field with general loss-cone distribution function: A kinetic approach, International Journal of Physical Sciences, 7(6), 893-900 (2012).
- F. Siddiqui, Gigabit Wireless Networking with IEEE 802.11ac: Technical Overview and Challenges, Journal of Networks, 10(3), 164-171 (2015).
- N. Eftekhari, M. Poyan and H. Alinejad-Rokny, Evaluation and Classifying Software Architecture Styles Due to Quality Attributes, Australian Journal of Basic and Applied Sciences, 5(11), 1251-1256 (2011).
- N. Gedik, Breast Cancer Diagnosis System via Contourlet Transform with Sharp Frequency Localization and Least Squares Support Vector Machines, Journal of Medical Imaging and Health Informatics, 5, 497-505 (2015).
- N. Lalithamani and M. Sabrigiriraj, Dual Encryption Algorithm to Improve Security in Hand Vein and Palm Vein-Based Biometric Recognition, Journal of Medical Imaging and Health Informatics, 5, 545-551 (2015).
- M. Khan and R. Jehangir,Fuzzy resolvability modulo fuzzy ideals, International Journal of Physical Sciences, 7(6), 953-956 (2012).
- M. Ravichandran and A.Shanmugam, Amalgamation of Opportunistic Subspace & Estimated Clustering on High Dimensional Data, Australian Journal of Basic and Applied Sciences, 8(3), 88-97, (2014).
- M. Zhang, Optimization of Inter-network Bandwidth Resources for Large-Scale Data Transmission, Journal of Networks, 9(3), 689-694 (2014).
- O. O. E. Ajibola, O. Ibidapo-Obe, and V. O. S. OIunloyo, A Model for the Management of Gait Syndrome in Huntington's Disease Patient, Journal of Bioinformatics and Intelligent Control, 3, 15-22 (2014).
- L. Z. Pei, T. Wei, N. Lin and Z. Y. Cai, Electrochemical Sensing of Histidine Based on the Copper Germanate Nanowires Modified Electrode, Journal of Bionanoscience, 9, 161-165 (2015).
- M. K. Elboree, Explicit Analytic Solution for the Nonlinear Evolution Equations using the Simplest Equation Method, Mathematical Sciences Letters, 3(1), 59-63 (2014).
- R. Yousef and T. Almarabeh, An enhanced requirements elicitation framework based on business process models, Scientific Research and Essays, 10(7), 279-286 (2015).
- K. Manimekalai and M.S. Vijaya, Taxonomic Classification of Plant Species Using Support Vector Machine, Journal of Bioinformatics and Intelligent Control, 3, 65-71 (2014).
- S. Rajalaxmi and S. Nirmala, Automated Endo Fitting Curve for Initialization of Segmentation Based on Chan Vese Model, Journal of Medical Imaging and Health Informatics, 5, 572-580 (2015).
- T. Mahmood and K. Hayat, Characterizations of Hemi-Rings by their Bipolar-Valued Fuzzy h-Ideals, Information Sciences Letters, 4(2), 51-59 (2015).
- Agarwal and N. Mittal, Semantic Feature Clustering for Sentiment Analysis of English Reviews, IETE Journal of Research, 60(6), 414-422 (2014).
- S. Radharani and M. L.Valarmathi, Content Based Watermarking Techniques using HSV and Fractal Dimension in Transform Domain, Australian Journal of Basic and Applied Sciences, 8(3), 112-119 (2014).
- H. W. and W. Wang, an Improved Artificial Bee Colony Algorithm and Its Application on Production Scheduling, Journal of Bioinformatics and Intelligent Control, 3, 153-159 (2014).
- H. Alinejad Rokny, M.M. Pedram, and H. Shirgahi, Discovered motifs with using parallel Mprefixspan method, Scientific Research and Essays, 6(20), 4220-4226 (2011).
- H. Alinejad-Rokny, M. Keikhay Farzaneh, A. Goran Orimi, M. M. Pedram and H. Ahangari Kiasari, Proposing a New Structure for Web Mining and Personalizing Web Pages, Journal of Emerging Technologies in Web Intelligence, 5(3), 287-295 (2013).
- L. Gupta,Effect of orientation of lunar apse on earthquakes, International Journal of Physical Sciences, 7(6), 974-981 (2012).
- S. Iftikhar, F. Ahmad and K. Fatima, A Semantic Methodology for Customized Healthcare Information Provision, Information Sciences Letters, 1(1), 49-59 (2012).
- P. D. Sia, Analytical Nano-Modelling for Neuroscience and Cognitive Science, Journal of Bioinformatics and Intelligent Control, 3, 268-272 (2014).
- C. Guler, Production of particleboards from licorice (Glycyrrhiza glabra) and European black pine (Pinus Nigra Arnold) wood particles, Scientific Research and Essays, 10(7), 273-278 (2015).
- Z. Chen and J. Hu, Learning Algorithm of Neural Networks on Spherical Cap, Journal of Networks, 10(3), 152-158 (2015).
- W. Lu, Parameters of Network Traffic Prediction Model Jointly Optimized by Genetic Algorithm, Journal of Networks, 9(3), 695-702 (2014).
- K. Boubaker,An attempt to solve neutron transport equation inside supercritical water nuclear reactors using the Boubaker Polynomials Expansion Scheme, International Journal of Physical Sciences, 7(19), 2730-2734 (2012).
- K. Abd-Rabou, Fixed Point Results in G-Metric Space, Mathematical Sciences Letters, 3(3), 141-146 (2014).
- Binu and M. Selvi, BFC: Bat Algorithm Based Fuzzy Classifier for Medical Data Classification, Journal of Medical Imaging and Health Informatics, 5, 599-606 (2015).
- C. Kamath, Analysis of Electroencephalogram Background Activity in Epileptic Patients and Healthy Subjects Using Dispersion Entropy, Journal of Neuroscience and Neuroengineering, 3, 101-110 (2014).
- G. Kaur and E. M. Bharti, Securing Multimedia on Hybrid Architecture with Extended Role-Based Access Control, Journal of Bioinformatics and Intelligent Control, 3, 229-233 (2014).
- M. Ramalingam and D. Rana, Impact of Nanotechnology in Induced Pluripotent Stem Cells-driven Tissue Engineering and Regenerative Medicine, Journal of Bionanoscience, 9, 13-21 (2015).
- M. Mokhtari, H. Jalalifar, H. Alinejad-Rokny and P. PourAfshary, Prediction of permeability from reservoir main properties using neural network, Scientific Research and Essays, 6(32), 6626-6635 (2011).
- R. Javanmard, K. Jeddisaravi, and H. Alinejad-Rokny, Proposed a New Method for Rules Extraction Using Artificial Neural Network and Artificial Immune System in Cancer Diagnosis, Journal of Bionanoscience, 7(6), 665-672 (2013).
- S. Downes, New Technology Supporting Informal Learning, Journal of Emerging Technologies in Web Intelligence, 2(1), 27-33 (2010).
- M. Pourshaikh, M. Poyan, H. Motameni and H. Alinejad-Rokny, Improving Web Engineering and Agile ICONIX Process, Middle East Journal of Scientific Research, 8(1), 274-281 (2011).
- R. Periyasamy, T. K. Gandhi, S. R. Das, A. C. Ammini and S. Anand, A Screening Computational Tool for Detection of Diabetic Neuropathy and Non-Neuropathy in Type-2 Diabetes Subjects, Journal of Medical Imaging and Health Informatics, 2, 222-229 (2012).
- Y. Qin, F. Wang and C. Zhou, A Distributed UWB-based Localization System in Underground Mines, Journal of Networks, 10(3), 134-140 (2015).
- H. Alinejad-Rokny, D. Ebrahimi and M. Davenport, A New Method to Avoid Errors Associated with the Analysis of Hypermutated Viral Sequences, International Conference on Bioinformatics, Sydney, (2014).
- P. Saxena and C. Ghosh, A review of assessment of benzene, toluene, ethylbenzene and xylene (BTEX) concentration in urban atmosphere of Delhi, International Journal of Physical Sciences, 7(6), 850-860 (2012).
- J. Hu, Z. Zhou and M. Teng, The Spatiotemporal Variation of Ecological Risk in the Lijiang River Basin Based on Land Use Change, Journal of Bionanoscience, 9, 153-160 (2015).
- N. Saleem, M. Ahmad, S. A. Wani, R. Vashnavi and Z. A. Dar, Genotype-environment interaction and stability analysis in Wheat (Triticum aestivum L.) for protein and gluten contents, Scientific Research and Essays, 10(7), 260-265 (2015).
- R. A. Rashwan and S. M. Saleh, A Coupled Fixed Point Theorem for Three Pairs of w-Compatible Mappings in G-metric spaces, Mathematical Sciences Letters, 3(1), 17-20 (2014).
- S. P. Singh and B. K. Konwar, Carbon Nanotube Assisted Drug Delivery of the Anti-Malarial Drug Artemesinin and Its Derivatives-A Theoretical Nanotechnology Approach, Journal of Bionanoscience,7, 630-636 (2013).
- R. Dinasarapu and S. Gupta, Biological Data Integration and Dissemination on Semantic Web-A Perspective, Journal of Bioinformatics and Intelligent Control, 3, 273-277 (2014).
- M. Poyan, R. Pourshaikh and H. Alinejad-Rokny, Conceptual Information Retrieval in Cross-Language Searches, Research Journal of Applied Sciences, Engineering and Technology, 4(12), 714-1720 (2012).
- W. Qiaonong, X. Shuang, and W. Suiren, Sparse Regularized Biomedical Image Deconvolution Method Based on Dictionary Learning, Journal of Bionanoscience, 9, 145-152 (2015).
- C. Prema and D. Manimegalai, Adaptive Color Image Steganography Using Intra Color Pixel Value Differencing, Australian Journal of Basic and Applied Sciences, 8(3), 161-167 (2014).
- R. Adollah, M. Y. Mashor, H. Rosline, and N. H. Harun, Multilevel Thresholding as a Simple Segmentation Technique in Acute Leukemia Images, Journal of Medical Imaging and Health Informatics, 2, 285-288 (2012).
- H. Uppili, Proton-Induced Synaptic Transistors: Simulation and Experimental Study, Journal of Neuroscience and Neuroengineering, 3, 117-129 (2014).
- Di Salvo, Deep inelastic processes and the equations of motion,International Journal of Physical Sciences,7(6), 867-892 (2012).
- H. Alinejad-Rokny, Proposing on Optimized Homolographic Motif Mining Strategy based on Parallel Computing for Complex Biological Networks, Journal of Medical Imaging and Health Informatics, 6(2), 416-424 (2016).
- A. M. Arafa, S. Z. Rida and H. Mohamed, An Application of the Homotopy Analysis Method to the Transient Behavior of a Biochemical Reaction Model, Information Sciences Letters, 3(1), 29-33 (2014).
- V. M. Somsikov, A. B. Andreyev and A. I. Mokhnatkin, Relation between classical mechanics and physics of condensed medium, International Journal of Physical Sciences, 10(3), 112-122 (2015).
- C. Krishnamoorthy, K. Rajamani, S. Mekala and S. Rameshkumar, Fertigation through trickle and micro sprinkler on flowering characters in cocoa (Theobroma cacao L.), Scientific Research and Essays, 10(7), 266-272 (2015).
- J. Peng, A New Model of Data Protection on Cloud Storage, Journal of Networks, 9(3), 666-671 (2014).
- S. Nageswari and V. Suresh Kumar, VCMIPWM Scheme to Reduce the Neutral-Point Voltage Variations in Three-Level NPC Inverter, IETE Journal of Research, 60(6),396-405 (2014).
- X. Ochoa, Connexions: A Social and Successful Anomaly among Learning Object Repositories, Journal of Emerging Technologies in Web Intelligence, 2(1), 11-22 (2010).
- Y.S. Chiu, What Can Signed Languages Tell Us About Brain? Journal of Neuroscience and Neuroengineering, 1, 54-60 (2012).
- M. Sadeghi and H. Alinejad-Rokny, On Covering of Products of T-Generalized State Machines, Mathematical Sciences Letters, 1(1), 43-52 (2012).
- K. Rezgui, H. Mhiri and K. Ghédira, Theoretical Formulas of Semantic Measure: A Survey, Journal of Emerging Technologies in Web Intelligence, 5(4), 333-342 (2013).
- K. Parwez and S. V. Budihal, Carbon Nanotubes Reinforced Hydroxyapatite Composite for Biomedical Application, Journal of Bionanoscience, 8, 61-65 (2014).
- H. El-Owaidy, A. Abdeldaim and A. A. El-Deeb, On Some New Retarded Nonlinear Integral Inequalities and Their Applications, Mathematical Sciences Letters, 3(3), 157-164 (2014).
- H. Zheng, J. Jie and Y. Zheng, Multi-Swarm Chaotic Particle Swarm Optimization for Protein Folding, Journal of Bionanoscience, 7, 643-648 (2013).
- H. Kamali-Bandpey, H. Alinejad-Rokny, H. Khanbabapour and F. Rashidinejad, Optimization of Firing System Utilizing Fuzzy Madm Method-Case study: Gravel Mine Project in Gotvand Olya Dam-Iran, Australian Journal of Basic and Applied Sciences, 5(12), 1089-1097 (2011).
- S. V. Sathyanarayana and K. N. Hari Bhat, Novel Scheme for Storage and Transmission of Medical Images with Patient Information Using Elliptic Curve Based Image Encryption Schemes with LSB Based Steganographic Technique, Journal of Medical Imaging and Health Informatics, 2, 15-24 (2012).
- Satyendra Sharma and Brahmjit Singh, Field Measurements for Cellular Network Planning, Journal of Bioinformatics and Intelligent Control, 2, 112-118 (2013).
- Y. Wang, An Approximate Algorithm for TSP with Four Vertices and Three Lines Inequality, Information Sciences Letters, 3(2), 41-44 (2014).
- S. P. Singh and B. K. Konwar, Insilico Proteomics and Genomics Studies on ThyX of Mycobacterium Tuberculosis, Journal of Bioinformatics and Intelligent Control, 2, 11-18 (2013).
- K. Kumar, A. K. Verma and R. B. Patel, Framework for Key Management Scheme in Heterogeneous Wireless Sensor Networks, Journal of Emerging Technologies in Web Intelligence, 3(4), 286-296 (2011).
- R. Bruck, H. Aeed, H. Shirin, Z. Matas, L. Zaidel, Y. Avni, and Z. Halpern, J. Hepatol. 31, 27 (1999).
- H. Alinejad-Rokny, A Method to Avoid Gapped Sequential Patterns in Biological Sequences: Case Study: HIV and Cancer Sequences, Journal of Neuroscience and Neuroengineering, 4, 48-52, (2015).
- V. Gupta, A Survey of Text Summarizers for Indian Languages and Comparison of their Performance, Journal of Emerging Technologies in Web Intelligence, 5(4), 361-366 (2013).
- M. Kaczmarek, A. Bujnowski, J. Wtorek, and A. Polinski, Multimodal Platform for Continuous Monitoring of the Elderly and Disabled, Journal of Medical Imaging and Health Informatics, 2, 56-63 (2012).
- H. Khanbabapour, H. Alinejad-Rokny and H. Kamali-Bandpey, The Best Transportation System Selection with Fuzzy Mmulti-Ccriteria Decision Making (Fuzzy MADM)-Case Study: Iran Persian Gulf Tunnel, Research Journal of Applied Sciences Engineering and Technology, 5(1), 1748-1758 (2012).
- H. Chemani, Correlation between milling time, particle size for stabilizing rheological parameters of clay suspensions in ceramic tiles manufacture, International Journal of Physical Sciences, 10(1), 46-53 (2015).
- S. Nadeem and S. Saleem, Theoretical Investigation of MHD Nanofluid Flow Over a Rotating Cone: An Optimal Solutions, Information Sciences Letters, 3(2), 55-62 (2014).
- M. Zamoum, M. Kessal,Analysis of cavitating flow through a venture, Scientific Research and Essays, 10(11), 383-391 (2015).
- H. Morad, GPS Talking For Blind People, Journal of Emerging Technologies in Web Intelligence, 2(3), 239-243 (2010).
- M. MirnabiBaboli, S. RashidiBajgan, and H. Alinejad-Rokny, The Enhancement of Network Lifetime by Mobile Node in OPP Routing of Wireless Sensor Network,Information Sciences Letters,4, 1-6(2015).
- D. Rawtani and Y. K. Agrawal, Study the Interaction of DNA with Halloysite Nanotube-Gold Nanoparticle Based Composite, Journal of Bionanoscience, 6, 95-98 (2012).
- V. Karthick and K. Ramanathan, Investigation of Peramivir-Resistant R292K Mutation in A (H1N9) Influenza Virus by Molecular Dynamics Simulation Approach, Journal of Bioinformatics and Intelligent Control, 2, 29-33 (2013).
- R. Uthayakumar and A. Gowrisankar, Generalized Fractal Dimensions in Image Thresholding Technique, Information Sciences Letters, 3(3), 125-134 (2014).
- I. Alavi, H. Alinejad-Rokny, M. Sadegh Zadeh, Prioritizing Crescive Plant Species in Choghart Iron Mine DesertRegion (Used method: Fuzzy AHP), Australian Journal of Basic and Applied Sciences, 5(12), 1075-1078 (2011).
- B. Ould Bilal, D. Nourou, C. M. F Kébé, V. Sambou, P. A. Ndiaye and M. Ndongo, Multi-objective optimization of hybrid PV/wind/diesel/battery systems for decentralized application by minimizing the levelized cost of energy and the CO2 emissions, International Journal of Physical Sciences, 10(5), 192-203 (2015).
- A. Maqbool, H. U. Dar, M. Ahmad, G. N. Malik, G. Zaffar, S. A. Mir and M. A. Mir, Comparative performance of some bivoltine silkworm (Bombyx mori L.) genotypes during different seasons, Scientific Research and Essays,10(12), 407-410 (2015).
- N. Seyedaghaee, S. Amirgholipour, H. Alinejad-Rokny and F. Rouhi, Strategic Planning Formulation by Using Reinforcement Learning, Research Journal of Applied Sciences, Engineering and Technology, 4(11), 1448-1454 (2012).
- R. B. Little, A theory of the relativistic fermionic spinrevorbital, International Journal of Physical Sciences, 10(1), 1-37 (2015).
- Z. Chen, F. Wang and Li Zhu, The Effects of Hypoxia on Uptake of Positively Charged Nanoparticles by Tumor Cells, Journal of Bionanoscience, 7, 601-605 (2013).
- H. Motameni, H. Alinejad-Rokny, M.M Pedram, Using Sequential Pattern Mining in Discovery DNA Sequences Contain Gap, American Journal of Scientific Research, 14(2011), 72-78 (2011).
- A.Kaur and V. Gupta, A Survey on Sentiment Analysis and Opinion Mining Techniques, Journal of Emerging Technologies in Web Intelligence, 5(4), 367-371(2013).
- P. Saxena and M. Agarwal, Finite Element Analysis of Convective Flow through Porous Medium with Variable Suction, Information Sciences Letters, 3(3), 97-101 (2014).
- J. G. Bruno, Electrophoretic Characterization of DNA Oligonucleotide-PAMAM Dendrimer Covalent and Noncovalent Conjugates, Journal of Bionanoscience, 9, 203-208 (2015).
- K. K. Tanaeva, Yu. V. Dobryakova, and V. A. Dubynin, Maternal Behavior: A Novel Experimental Approach and Detailed Statistical Analysis, Journal of Neuroscience and Neuroengineering, 3, 52-61 (2014).
- E. Zaitseva and M. Rusin, Healthcare System Representation and Estimation Based on Viewpoint of Reliability Analysis, Journal of Medical Imaging and Health Informatics, 2, 80-86 (2012).
- R. Ahirwar, P. Devi and R. Gupta, Seasonal incidence of major insect-pests and their biocontrol agents of soybean crop (Glycine max L. Merrill), Scientific Research and Essays, 10(12), 402-406 (2015).
- H. Boussak, H. Chemani and A. Serier, Characterization of porcelain tableware formulation containing bentonite clay, International Journal of Physical Sciences, 10(1), 38-45 (2015).
- Q. Xiaohong, and Q. Xiaohui, an Evolutionary Particle Swarm Optimizer Based on Fractal Brownian Motion, Journal of Computational Intelligence and Electronic Systems, 1, 138 (2012).
- G. Minhas and M. Kumar, LSI Based Relevance Computation for Topical Web Crawler, Journal of Emerging Technologies in Web Intelligence, 5(4), 401-406 (2013).
- N. Seyedaghaee, S. Rahati, H. Alinejad-Rokny and F. Rouhi, An Optimized Model for the University Strategic Planning, International Journal of Basic Sciences & Applied Research, 2(5), 500-505 (2013).
- H. Alinejad-Rokny, H. Pourshaban, A. Goran and M. MirnabiBaboli,Network Motifs Detection Strategies and Using for Bioinformatic Networks, Journal of Bionanoscience, 8(5), 353-359 (2014).
- Y. Shang, Efficient strategies for attack via partial information in scale-free networks, Information Sciences Letters, 1(1), 1-5 (2012).
- M. Ahmadinia, H. Alinejad-Rokny, and H. Ahangarikiasari, Data Aggregation in Wireless Sensor Networks Based on Environmental Similarity: A Learning Automata Approach, Journal of Network, 9(10), 2567-2573(2014).
- I.Rathore and J. C. Tarafdar, Perspectives of Biosynthesized Magnesium Nanoparticles in Foliar Application of Wheat Plant,Journal of Bionanoscience,9, 209-214 (2015).
- I. Alavi and H. Alinejad-Rokny, Comparison of Fuzzy AHP and Fuzzy TOPSIS Methods for Plant Species Selection (Case study: Reclamation Plan of Sungun Copper Mine; Iran, Australian Journal of Basic and Applied Sciences, 5(12), 1104-1113 (2011).
- H. Yan and H. Hu, Research and Realization of ISIC-CDIO Teaching Experimental System Based on RFID Technology of Web of Things, Journal of Bionanoscience, 7, 696-702 (2013).
- R. Teles, B. Barroso, A. Guimaraes and H. Macedo, Automatic Generation of Human-like Route Descriptions: A Corpus-driven Approach, Journal of Emerging Technologies in Web Intelligence, 5(4), 413-423 (2013).
- E. S. Hui, Diffusion Magnetic Resonance Imaging of Ischemic Stroke, Journal of Neuroscience and Neuroengineering, 1, 48-53 (2012).
- O. E. Emam, M. El-Araby and M. A. Belal, On Rough Multi-Level Linear Programming Problem, Information Sciences Letters, 4(1), 41-49 (2015).
- B. Prasad, D.C. Dimri and L. Bora,Effect of pre-harvest foliar spray of calcium and potassium on fruit quality of Pear cv. Pathernakh, Scientific Research and Essays, 10(11), 392-396 (2015).
- H. Parvin, H. Alinejad-Rokny and M. Asadi, An Ensemble Based Approach for Feature Selection, Australian Journal of Basic and Applied Sciences, 7(9), 33-43 (2011).
- G. Singh, Optimization of Spectrum Management Issues for Cognitive Radio, Journal of Emerging Technologies in Web Intelligence, 3(4), 263-267 (2011).
- D. Madhuri, Linear Fractional Time Minimizing Transportation Problem with Impurities, Information Sciences Letters, 1(1), 7-19 (2012).
- A. D. Dele, Oscilating magnetic field an anti malaria therapy, International Journal of Physical Sciences, 10(10), 329-334 (2015).
- J. Mayevsky, J. Sonn and E. Barbiro-Michaely, Physiological Mapping of Brain Functions In Vivo: Surface Monitoring of Hemodynamic Metabolic Ionic and Electrical Activities in Real-Time, Journal of Neuroscience and Neuroengineering, 2, 150-177 (2013).
- M. Bakhshi, A. Gorji, M. Hosseinzade H, M. Jamshidi, G. Mohammad-Alinejad, A New Die Design for Sheet Hydroforming of Complex Industrial Parts, AdvancedMaterials Research, 83: 1084-1091, (2010).
- M. Hosseinzade, and A. Zamanib, Experimental and numerical investigation of tube sinking of rectangular tubes from round section, International Journal of Engineering and Technology,2(5): 407-419 (2014).
- M. Hosseinzadeh, M. Bakhshi-Jooybari, M. Shakeri, H. Mostajeran, and H. Gorji, Application of Taguchi Method in Optimization of New Hydroforming Die Design, SteelResearch International, 81(9): 647-650, (2010).
- M. Hosseinzadeh, S. A. Zamani, and A. Taheri, An Optimization of the New Die Design of Sheet Hydroforming by Taguchi Method, Advanced Materials Research, 337: 294-299 (2011).
- E. Nateghi, and M. Hosseinzadeh, Experimental investigation into effect of cooling of traversed weld nugget on quality of high-density polyethylene joints, The International Journal ofAdvanced Manufacturing Technology, (2015): 1-14.



